Freitag, 31. Dezember 2010
Freitag, 19. November 2010
Mittwoch, 20. Oktober 2010
Currency Conversion
Boyan Penev writes in his Blog about Currency Conversion in SSAS. He provides a lot of interesting links and includes also practical examples. His Blog is absolutly worth reading (and is now included into the link section of this page).
Mittwoch, 29. September 2010
Cube documentation with DMV data
The FrogBlog shows how to generate a SSRS documentation for a cube by using DMVs via LinkedServer access:
Mittwoch, 8. September 2010
Linked Cubes
Again only a link ...
Chris Webb wrote in his Blog about the question:
Chris Webb wrote in his Blog about the question:
whether, if you have multiple fact tables, you should create one big cube with multiple measure groups or multiple cubes each with a single measure group.Wenn he says that "Linked measure groups are a pain to manage" I have to agree...
Freitag, 18. Juni 2010
Dynamic Sets with SQL Server 2008 R2 and Excel 2010
Thomas Ivarsson shows in his Blog that the use of dynamic sets is much improved for the combination of SQL Server 2008 R2 and Excel 2010.
Mittwoch, 2. Juni 2010
Partitioning
Teo Lachev writes in his Blog about the rules for the definition of partitions. For him partitioning is mainly a feature to improve the manageability of cubes and not to improve query performance - and I guess he's right.
Freitag, 14. Mai 2010
Process Update
In his Blog Chris Webb has published a short explanation of the consequences of ProcessUpdate on a dimension for the aggregations on related partitions. To make it even shorter: It seems to be a good idea to do a ProcessIndex on those partitions after the ProcessUpdate for the dimension.
Mittwoch, 14. April 2010
I/O Performance
Theo Lachev explains in his Blog why the SQL Profiler does not tell you the truth about I/O waits in SSAS: it's "because the Started/Finished reading data from the partition events include also the time spent in aggregating data and this time may be significant". He suggests to use the Xperf tool from the Windows Performance Toolkit instead and provides links to some short introductions that show how to use the tool.
Apart from this he also suggests to use solid state disks (SSD) when the storage engines spends a lot of time reading data (but "There needs no Ghost, my lord, come from the grave
Apart from this he also suggests to use solid state disks (SSD) when the storage engines spends a lot of time reading data (but "There needs no Ghost, my lord, come from the grave
/To tell us this.")
Donnerstag, 18. März 2010
Save your day with ProcessIncremental
Who claims not to have too long processing times in real-world analytic databases either is a lyer ...
... or he has the SSAS Enterprise Edition installed with the great "ProcessIncremental" processing mode. In principal, this is a clever usage of the "Partition Merge" option in that it allows to feed a tiny data set that is disjunct from the last processing slice into a temporary partition which is then merged with an existing partition that is to be extended.
In our current project, where we tried to setup a "ProcessUpdate" szenario, the complexity of dimension, partition changes and ProcessIndex calls had summed up to a period that was nearly as long as a full "Process" (~2h for 5GB/2 years of business data).
Now it seems that we will come down to around 10-20min which should give us a nice slap to our backs unless I did oversee something stupid, here.
... or he has the SSAS Enterprise Edition installed with the great "ProcessIncremental" processing mode. In principal, this is a clever usage of the "Partition Merge" option in that it allows to feed a tiny data set that is disjunct from the last processing slice into a temporary partition which is then merged with an existing partition that is to be extended.
In our current project, where we tried to setup a "ProcessUpdate" szenario, the complexity of dimension, partition changes and ProcessIndex calls had summed up to a period that was nearly as long as a full "Process" (~2h for 5GB/2 years of business data).
Now it seems that we will come down to around 10-20min which should give us a nice slap to our backs unless I did oversee something stupid, here.
Dienstag, 16. März 2010
Data Quality
Hilmar Buchta mentions in his Blog an new codeplex project with a (NUnit-based) testing suite to monitor the data quality in BI solutions. Seems to be quite useful.
Montag, 8. März 2010
Setting Locale-Specific Naming Size Information
In SSAS 2008, there is the possibility to translate a key-only attribute just on a locale-specific basis: The name in the default attribute properties is left empty and the individual name columns are associated on a per-attribute/locale basis in the translation tab.
When the size of those columns changes, there is now the need to adapt it also in the name mapping. The place to to this is not quite obvious since the name property of the attribute is now empty: When selecting the attribute in the translation tab, go to the properties view and unfold the "CaptionColumn" property. Here you will find the important mapping information that you need to manipulate.
When the size of those columns changes, there is now the need to adapt it also in the name mapping. The place to to this is not quite obvious since the name property of the attribute is now empty: When selecting the attribute in the translation tab, go to the properties view and unfold the "CaptionColumn" property. Here you will find the important mapping information that you need to manipulate.
Various (Non-)Ways for Hiding Trivial Members in Hierarchies
This is a link-collection that Martin has been doing when investigating, how and why the auto-hide-member of trivial members (they show a single child with the same semantics and are mostly artificially introduced to render unbalanced parent-child tress into balanced md-trees) does not work with Excel 2007 and SSAS 2008.
The Microsoft Documentation for the HideMemberIf-Property mentions the MDX Compatibility-Level of connections.
Chris Webb and Mark Russo describe how Excel 2007 overwrites the property value no matter what you specified.
There was a time when you could set the level in the registry back with SSAS 2000.
http://social.msdn.microsoft.com/forums/en-US/sqlanalysisservices/thread/aeca1ce0-e6aa-4fdc-b604-cc0e27b7ab5a/
--> in 2005 + 2008 ist der Registry-Eintrag nicht vorgesehen
Greg Galloway hacks Excel to be content overwriting only a first fake property:
Extended Properties="MDX Compatibility=2";MDX Compatibility=2;
However, in our experiments, this rendered the whole subbranch invisible.
Oh no, we do not sacrifice so much for that functionality.
The Microsoft Documentation for the HideMemberIf-Property mentions the MDX Compatibility-Level of connections.
Chris Webb and Mark Russo describe how Excel 2007 overwrites the property value no matter what you specified.
There was a time when you could set the level in the registry back with SSAS 2000.
http://social.msdn.microsoft.com/forums/en-US/sqlanalysisservices/thread/aeca1ce0-e6aa-4fdc-b604-cc0e27b7ab5a/
--> in 2005 + 2008 ist der Registry-Eintrag nicht vorgesehen
Greg Galloway hacks Excel to be content overwriting only a first fake property:
Extended Properties="MDX Compatibility=2";MDX Compatibility=2;
However, in our experiments, this rendered the whole subbranch invisible.
Oh no, we do not sacrifice so much for that functionality.
Freitag, 19. Februar 2010
Collation
Donnerstag, 11. Februar 2010
Freitag, 29. Januar 2010
The difference between Order By Name and Order By Key in trivial attributes
This is a straigthforward follow-up to the last post.
Suppose you have a trivial attribute, i.e., its key is mapped to a single column of a relational data source. Its name and value has been ommitted, i.e., corresponds to a representation of the key.
Now Order By Name (which should be the default) will lead to a lexicographic order based on the representation while only Order By Key will use the natural ordering of the underlying data type.
I´m sure you or the various books of your choices did know this already. But I didn´t.
Suppose you have a trivial attribute, i.e., its key is mapped to a single column of a relational data source. Its name and value has been ommitted, i.e., corresponds to a representation of the key.
Now Order By Name (which should be the default) will lead to a lexicographic order based on the representation while only Order By Key will use the natural ordering of the underlying data type.
I´m sure you or the various books of your choices did know this already. But I didn´t.
Dienstag, 26. Januar 2010
The difference between Names and descriptive Attributes
Depending on the configuration of your SSAS landscape (DB/OS/Locale of the data source, OS/Server Locale and Column Collation of the SSAS machine/cluster), you can get very strange processing errors in your dimensions especially related to character-based attributes/names.
For example, the default collation settings in SSAS (ignore whitespaces, case-insensitivity) will usually unify more (European/German-rooted) strings than a "distinct" selection in the database of your choice. NULL entries which SSAS cannot stand at all in dimension processing are also a constant cause of problems in that respect ...
If you now wonder, why this leads to processing errors in certain attributes (duplicate key error) and not in others, please remind the setup of each attribute into a key and a name column (the latter pointing to the former in the standard-case).
One of the fundamental differences between the two is that a "select distinct" of the key columns MUST NOT have two rows which will be unified by SSAS collation processing while this is not necessarily true for name columns in which case an arbitrary value is taken as the representative.
For example, the default collation settings in SSAS (ignore whitespaces, case-insensitivity) will usually unify more (European/German-rooted) strings than a "distinct" selection in the database of your choice. NULL entries which SSAS cannot stand at all in dimension processing are also a constant cause of problems in that respect ...
If you now wonder, why this leads to processing errors in certain attributes (duplicate key error) and not in others, please remind the setup of each attribute into a key and a name column (the latter pointing to the former in the standard-case).
One of the fundamental differences between the two is that a "select distinct" of the key columns MUST NOT have two rows which will be unified by SSAS collation processing while this is not necessarily true for name columns in which case an arbitrary value is taken as the representative.
Quasi-Cursor-Reading of Large Cellsets
One annoyance especially when batch-testing Cubes/Dimensions against the relational data source is that the MDX/XMLA-Architecture has no concept of continuation or open-cursor-reading.
And we all know how soon SSMS or MDX Studio present an OutOfMemoryException!
One particularly useful construct in that regard is the
And we all know how soon SSMS or MDX Studio present an OutOfMemoryException!
One particularly useful construct in that regard is the
SubSet(Set,Position,Length)MDX-function which can be easily used to technically partition large result spaces into manageable junks.
Montag, 25. Januar 2010
Grouping in SQL and MDX
In his Blog MDX equivalent of a filtered GROUP BY in SQL Darren Gosbell shows how to translate a SQL query (with a restriction in the WHERE-clause and a GROUP BY aggregating elements of a higher hierarchy level) into a corresponding MDX query. Although MDX looks like SQL it's something completly different, so every translation is beneficial.
Freitag, 22. Januar 2010
Strange Perspectives
In SSAS Persepctives are a very useful tool to control the visibility of objects (dimesions, measures, hierarchies etc.). They represent subsets of cubes and define Views with the relevant data for a specific audience. In the Perspectives tab of the cube designer in BIDS I can exclude objects, that I want to hide from my users. But obviously sometimes SSAS does not believe that I know what I do:
In the following example I defined a simple cube with only one measure group and some dimensions. In addition I created a calculation TestQuantity. In the Perspectives tab I choosed to include all the measures and the additional calculation:

In the browser we see the expected elements:

Now I exclude some of my measures from the Perspective:

And again I get the expected selection:

But when I exclude all the basic measures and want to include only my calculation, SSAS apparently starts to question my accountability:
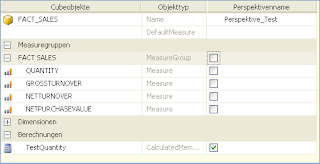
The result again contains all the measures of the group, I wanted to exclude:
Perhaps SSAS believes that a cube (or a cube view) without measures is not very beneficial, but since the calculation TestQuantity was not excluded, I see no reason for this implicit addition of objects.
For the sake of completeness a link to William Pearson's article on Perspectives in the Database Journal and another one to the (books online) documentation.
In the following example I defined a simple cube with only one measure group and some dimensions. In addition I created a calculation TestQuantity. In the Perspectives tab I choosed to include all the measures and the additional calculation:

In the browser we see the expected elements:

Now I exclude some of my measures from the Perspective:

And again I get the expected selection:

But when I exclude all the basic measures and want to include only my calculation, SSAS apparently starts to question my accountability:

The result again contains all the measures of the group, I wanted to exclude:
Perhaps SSAS believes that a cube (or a cube view) without measures is not very beneficial, but since the calculation TestQuantity was not excluded, I see no reason for this implicit addition of objects.
For the sake of completeness a link to William Pearson's article on Perspectives in the Database Journal and another one to the (books online) documentation.
Mittwoch, 20. Januar 2010
Official release date for SQL Server 2008 R2
According to the Data Platform Insider Blog ''SQL Server 2008 R2'' received an official release date and will be available by May 2010.
Sonntag, 10. Januar 2010
Dynamic Management Views (DMV) in SSAS
Vincent Rainardi wrote in his Blog SSAS DMV (Dynamic Management View) on a topic we tried already to cover here some weeks ago. The article provides some interesting links to Blogs that explain who to join the results of different DMVs together.
Mittwoch, 6. Januar 2010
Debugging Attribute Relationships in the ROLAP Basis
I guess that this is quite obvious and could as well be published in our ROLAP blog, but just for the sake of completeness:
The following SQL-Statement lists all values of a source attribute
Extending this a bit delivers all the bad rows:
The following SQL-Statement lists all values of a source attribute
srcin your dimension source table/view
dimwhich violate an attribute relationship (path) to a destination attribute
dest.
select src from dim group by src having count(distinct dest)>1
Extending this a bit delivers all the bad rows:
select * from dim where src in (select src from dim group by src having count(distinct dest)>1)
Dienstag, 5. Januar 2010
Excel and MDX multiselect problems revisited
Multiselect problems ins SSAS 2005 ff come in several forms. Today, I want to take a look at several forms of multiselect problems, how they interact with Excel as a MDX client and how they can be avoided. Let's first look a problem that can be easily detected.
In his blog article Multiselect friendly MDX for calculations looking at current coordinate
Mosha Pasumansky explains how multiselect problems that use a set in the current coordinate occur and how they can be avoided. Let's show an example for the classical Adventure Works Cube. I use SSAS 2008 and Excel 2007. Let's define the sales amount for the year before as follows:
create member [Measures].[Prior Year Sales Amount] as ([Measures].[Sales Amount],ParallelPeriod([Date].[Calendar].[Calendar Year],1,[Date].[Calendar].CurrentMember));
Let's look at a simple example in Excel 2008:

So far, it works fine, now let's filter on the dates, first on calendar year 2002.

It still works fine. Now let's filter on two months, say May and June 2002. Here's the result.
It doesn't work anymore because now, the current coordinate is a set. Here's the query:
SELECT {[Measures].[Sales Amount],[Measures].[Prior Year Sales Amount]} ON COLUMNS , NON EMPTY Hierarchize({DrilldownLevel({[Product].[Product Categories].[All Products]})}) ON ROWS FROM (SELECT ({[Date].[Calendar].[Month].&[2002]&[5],[Date].[Calendar].[Month].&[2002]&[6]}) ON COLUMNS FROM [Adventure Works])
Amount],[Measures].[Prior Year Sales Amount]} ON COLUMNS , NON EMPTY Hierarchize({DrilldownLevel({[Product].[Product Categories].[All Products]})}) ON ROWS FROM (SELECT ({[Date].[Calendar].[Month].&[2002]&[5],[Date].[Calendar].[Month].&[2002]&[6]}) ON COLUMNS FROM [Adventure Works])
The set occurs in the subselect that Excel 2007 uses to implement the filter. If we do the same in Excel 2003, we get a similar result. it doesn't work but we get a least an error.
Now, the query us es a where clause and a calculated member to represent the set. Here's the query:
es a where clause and a calculated member to represent the set. Here's the query:
WITH MEMBER [Date].[Calendar].[XL_QZX] AS 'Aggregate({[Date].[Calendar].[Month].&[2002]&[6],[Date].[Calendar].[Month].&[2002]&[5]})' SELECT {[Measures].[Sales Amount],[Measures].[Prior Year Sales Amount]} ON COLUMNS , NON EMPTY Hierarchize(AddCalculatedMembers({DrilldownLevel({[Product].[Product Categories].[All Products]})})) ON ROWS FROM [Adventure Works] WHERE ([Date].[Calendar].[XL_QZX])
The error basically states the the CurrentMember function, which is used inside the ParallelPeriods function of our calculated measure [Prior Year Sales Amount] now contains a set.
A simple try of the same in Excel 2010 beta also shows that is currently does not work (even if you use the new SSAS 2008 R2 CTP).
Let's summarize: Calculations that use CurrentMember (or functions that use CurrentMember) are not multiselect-safe in Excel 2003, 2007 and ,at least up to now, in Excel 2010.
A possible workaround is described in Korrekte MDX-Berechnungen mit den Analysis Services trotz multiselect. The idea is to add a named calcuation in the data source view and to scope this calculation later on. Alternatively, you can just live with it, you just get no result or an error.
While the first problem can be easily detected Excel(you get no results or an error), the following problem is more subtle and cannot easily be detected. It occurs in Excel version 2007 (at up to now in 2010 beta). Let us again show an example in the adventure works cube. We define
Here is a simple excel 2007 example:
Let's now filter on the products dimension.We restrict to Accessories and Bikes and also leave out the touring bikes. Here's the result:
Well nice try, but unfortunately a wrong result. The visual totals are wrong, the sum of bikes should be 103 and the total 138. Let's look at the query:
SELECT NON EMPTY
Hierarchize(DrilldownMember({{DrilldownLevel({[Product].[Product Categories].[All Products]})}}, {[Product].[Product Categories].[Category].&[1]})) DIMENSION PROPERTIES PARENT_UNIQUE_NAME,[Product].[Product Categories].[Subcategory].[Category] ON COLUMNS
FROM
(SELECT ({[Product].[Product Categories].[Subcategory].&[2], [Product].[Product Categories].[Subcategory].&[1],
[Product].[Product Categories].[Category].&[4]}) ON COLUMNS
FROM [Adventure Works]) WHERE ([Measures].[Number of Products]
)
The filter step in Excel 2007 is implemented by a subselect. Unfortunately, the subselect does not change the current coordinate and thus the query execution context is the [All] member of the product dimension. And indead, the totals and subtotals are those for an unfiltered query.
A solution is to rely on a feature of SSAS2008, dynamic sets. The following solves the problem for SSAS 2008 and Excel 2007 and 2010.
create dynamic set Products as [Product].[Product].[Product]; create member[Measures].[Number of Products]
as count(existing(Products));
Here's the result:

Although Excel 2003 doesn't have subselect problems (it does not generate queries that use subselect), this solution does not work for Excel 2003 (the generated query does not benefit from the dynamic set, i.e., the results are still wrong.
Additionally, the problem still exists if we use different measures like Adventure Works
[Measures].[Ratio to Parent Product] because here, dynamic sets cannot help to solve the problem. Let's show this in the next example:

Now let's filter again:

Wow, amazing, all ratio to parent values are wrong, column real ratio gives you the correct values. Again, this is the effect of the subselect, that implements the filter. The current coordinate does not change, thus you see values of the form sum of filtered bikes / unfiltered parent of bikes, i.e. the 73,15% in the bikes row is equal to $80.324,94 / $109.809.274,20 (unfiltered total). The real ratios are in column "real ratio".
This also does not work in Excel 2010, but Excel 2003 computes correct values:

A solution to solve this problem in Excel 2007 and 2010 uses the same idea above, adding a hard measure (named calculation) together with scoping.
Let's summarize our results:
"The current coordinate is a set"-problem occurs in Excel versions 2003, 2007 and 2010 beta. You can either live with it (your get no result or an error) or you have to define a hard measure and scope it.
The "subselect and current coordinate"-problem occurs only in Excel versions 2007 and 2010 beta as these Excel versions rely on subselect to implement filters. Sometimes this problem can be circumvented by the use of dynamic sets (if your calculated measures relies on dynamically counting a set). In other cases, you have to define a hard measure and scope it.
The current coordinate is a set
In his blog article Multiselect friendly MDX for calculations looking at current coordinate
Mosha Pasumansky explains how multiselect problems that use a set in the current coordinate occur and how they can be avoided. Let's show an example for the classical Adventure Works Cube. I use SSAS 2008 and Excel 2007. Let's define the sales amount for the year before as follows:
create member [Measures].[Prior Year Sales Amount] as ([Measures].[Sales Amount],ParallelPeriod([Date].[Calendar].[Calendar Year],1,[Date].[Calendar].CurrentMember));
Let's look at a simple example in Excel 2008:

So far, it works fine, now let's filter on the dates, first on calendar year 2002.

It still works fine. Now let's filter on two months, say May and June 2002. Here's the result.
It doesn't work anymore because now, the current coordinate is a set. Here's the query:
SELECT {[Measures].[Sales
 Amount],[Measures].[Prior Year Sales Amount]} ON COLUMNS , NON EMPTY Hierarchize({DrilldownLevel({[Product].[Product Categories].[All Products]})}) ON ROWS FROM (SELECT ({[Date].[Calendar].[Month].&[2002]&[5],[Date].[Calendar].[Month].&[2002]&[6]}) ON COLUMNS FROM [Adventure Works])
Amount],[Measures].[Prior Year Sales Amount]} ON COLUMNS , NON EMPTY Hierarchize({DrilldownLevel({[Product].[Product Categories].[All Products]})}) ON ROWS FROM (SELECT ({[Date].[Calendar].[Month].&[2002]&[5],[Date].[Calendar].[Month].&[2002]&[6]}) ON COLUMNS FROM [Adventure Works]) The set occurs in the subselect that Excel 2007 uses to implement the filter. If we do the same in Excel 2003, we get a similar result. it doesn't work but we get a least an error.
Now, the query us
 es a where clause and a calculated member to represent the set. Here's the query:
es a where clause and a calculated member to represent the set. Here's the query:WITH MEMBER [Date].[Calendar].[XL_QZX] AS 'Aggregate({[Date].[Calendar].[Month].&[2002]&[6],[Date].[Calendar].[Month].&[2002]&[5]})' SELECT {[Measures].[Sales Amount],[Measures].[Prior Year Sales Amount]} ON COLUMNS , NON EMPTY Hierarchize(AddCalculatedMembers({DrilldownLevel({[Product].[Product Categories].[All Products]})})) ON ROWS FROM [Adventure Works] WHERE ([Date].[Calendar].[XL_QZX])
The error basically states the the CurrentMember function, which is used inside the ParallelPeriods function of our calculated measure [Prior Year Sales Amount] now contains a set.
A simple try of the same in Excel 2010 beta also shows that is currently does not work (even if you use the new SSAS 2008 R2 CTP).
Let's summarize: Calculations that use CurrentMember (or functions that use CurrentMember) are not multiselect-safe in Excel 2003, 2007 and ,at least up to now, in Excel 2010.
A possible workaround is described in Korrekte MDX-Berechnungen mit den Analysis Services trotz multiselect. The idea is to add a named calcuation in the data source view and to scope this calculation later on. Alternatively, you can just live with it, you just get no result or an error.
subselects and the current coordinate´problem
While the first problem can be easily detected Excel(you get no results or an error), the following problem is more subtle and cannot easily be detected. It occurs in Excel version 2007 (at up to now in 2010 beta). Let us again show an example in the adventure works cube. We define
create member [Measures].[Number of Products]
as
Count(Existing([Product].[Product].[Product].MEMBERS));
Here is a simple excel 2007 example:

Let's now filter on the products dimension.We restrict to Accessories and Bikes and also leave out the touring bikes. Here's the result:

Well nice try, but unfortunately a wrong result. The visual totals are wrong, the sum of bikes should be 103 and the total 138. Let's look at the query:
SELECT NON EMPTY
Hierarchize(DrilldownMember({{DrilldownLevel({[Product].[Product Categories].[All Products]})}}, {[Product].[Product Categories].[Category].&[1]})) DIMENSION PROPERTIES PARENT_UNIQUE_NAME,[Product].[Product Categories].[Subcategory].[Category] ON COLUMNS
FROM
(SELECT ({[Product].[Product Categories].[Subcategory].&[2], [Product].[Product Categories].[Subcategory].&[1],
[Product].[Product Categories].[Category].&[4]}) ON COLUMNS
FROM [Adventure Works]) WHERE ([Measures].[Number of Products]
)
The filter step in Excel 2007 is implemented by a subselect. Unfortunately, the subselect does not change the current coordinate and thus the query execution context is the [All] member of the product dimension. And indead, the totals and subtotals are those for an unfiltered query.
A solution is to rely on a feature of SSAS2008, dynamic sets. The following solves the problem for SSAS 2008 and Excel 2007 and 2010.
create dynamic set Products as [Product].[Product].[Product]; create member[Measures].[Number of Products]
as count(existing(Products));
Here's the result:

Although Excel 2003 doesn't have subselect problems (it does not generate queries that use subselect), this solution does not work for Excel 2003 (the generated query does not benefit from the dynamic set, i.e., the results are still wrong.
Additionally, the problem still exists if we use different measures like Adventure Works
[Measures].[Ratio to Parent Product] because here, dynamic sets cannot help to solve the problem. Let's show this in the next example:

Now let's filter again:

Wow, amazing, all ratio to parent values are wrong, column real ratio gives you the correct values. Again, this is the effect of the subselect, that implements the filter. The current coordinate does not change, thus you see values of the form sum of filtered bikes / unfiltered parent of bikes, i.e. the 73,15% in the bikes row is equal to $80.324,94 / $109.809.274,20 (unfiltered total). The real ratios are in column "real ratio".
This also does not work in Excel 2010, but Excel 2003 computes correct values:

A solution to solve this problem in Excel 2007 and 2010 uses the same idea above, adding a hard measure (named calculation) together with scoping.
Let's summarize our results:
"The current coordinate is a set"-problem occurs in Excel versions 2003, 2007 and 2010 beta. You can either live with it (your get no result or an error) or you have to define a hard measure and scope it.
The "subselect and current coordinate"-problem occurs only in Excel versions 2007 and 2010 beta as these Excel versions rely on subselect to implement filters. Sometimes this problem can be circumvented by the use of dynamic sets (if your calculated measures relies on dynamically counting a set). In other cases, you have to define a hard measure and scope it.
Abonnieren
Posts (Atom)